Negative Sampling
Introduction
In the ranking stage, it is common to utilize various sophisticated models, while the recall model is typically kept simple in comparison. This is primarily due to the significantly smaller number of samples processed in the ranking stage compared to the recall stage. Consequently, the selection of appropriate samples during the recall phase becomes crucial, and one key issue in the recall stage is the selection of negative samples.
According to Facebook’s research1, non-click impressions cannot be used as negative samples. A model trained using non-click impressions as negatives has significantly worse model recall compared to using random negatives, with an absolute regression in recall of 55% for the people embedding model. This finding contradicts the ideas of some colleagues, since non-click impressions have several straightforward properties that could be quite useful:
- Non-click impressions are more likely to be items that the user is not interested in compared to random sampling.
- The scale of non-click impressions is much smaller, which makes them faster to process.
In some sense, using non-click impression samples as negative samples can improve offline training performance. However, in the online stage, the model recall is significantly worse. The key reason for this is that the data distribution of offline training does not align with the online stage. The offline data distribution should always match the online data distribution.
Non-click impression samples are the hard cases that successfully pass through the recall and cascade stages and ultimately get displayed to the user. Therefore, they might match the query in one or multiple factors, while the majority of items in the online environment do not match the query at all. Having all negatives be hard negatives will change the representativeness of the training data for the real retrieval task, which might impose non-trivial bias to the learned embeddings.1
Random Sampling
Based on the analysis above, Facebook uses random sampling as negative samples. This approach is adopted because the majority of items are irrelevant to the user query during serving, and random sampling effectively simulates the online data distribution. However, selecting samples from the entire item set with equal probability is not reasonable due to the uneven distribution of impressions and clicks among items. A small number of popular items often dominate the majority of impressions and clicks, creating an imbalanced distribution.2
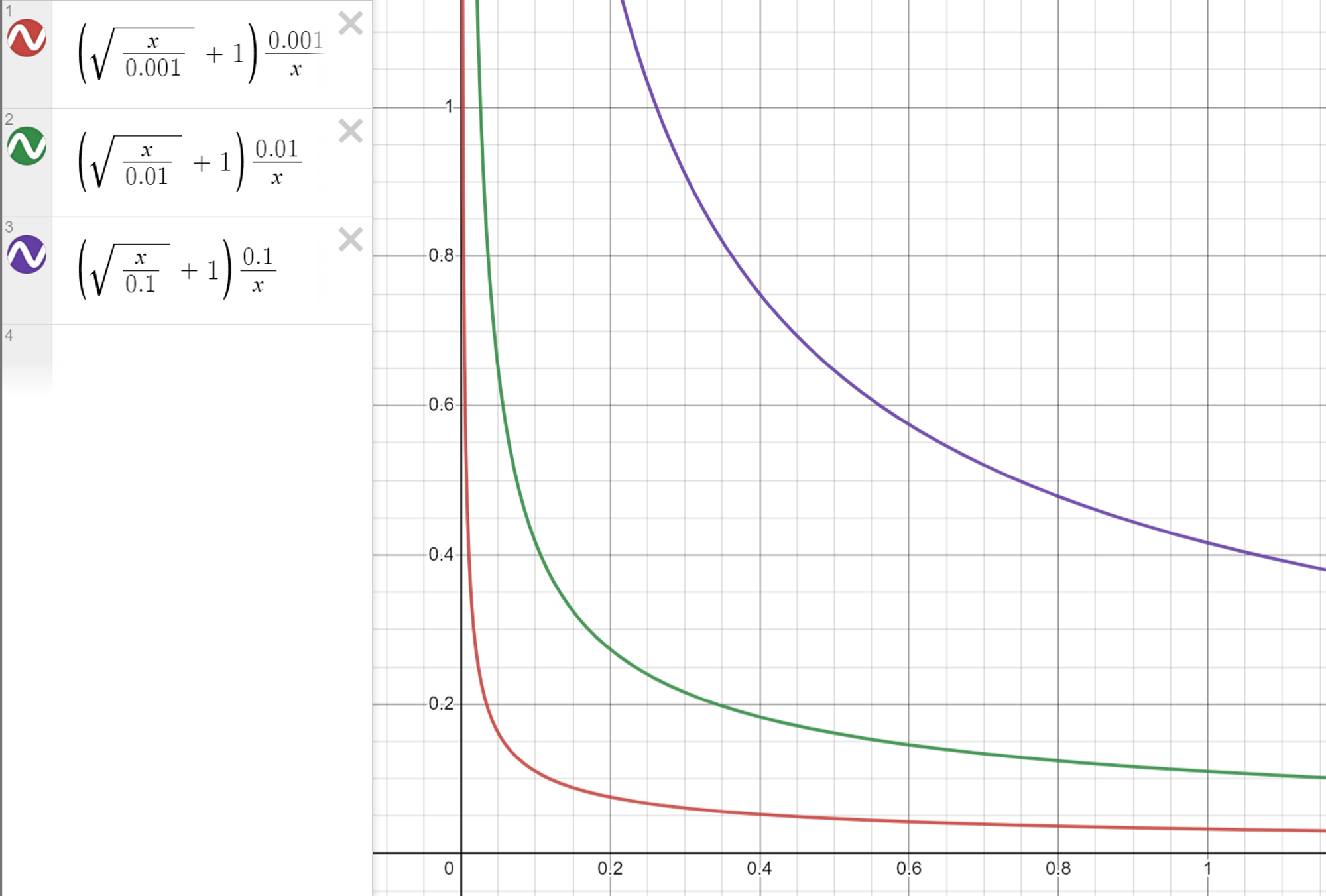
Therefore, when selecting positive samples, it is necessary to downsample, which means reducing the probability of sampling popular items.:
\[p_i^+ = \left(\sqrt{\frac{z(w_i)}{a}} + 1\right) \frac{a}{z(w_i)}\]where $z(w_i)$ is the number of impressions of item $i$ in the training set. As shown in the figure, smaller values of the hyper-parameter $a$ result in more severe suppression of hot items.
On the contrary, when sampling negative examples, we need to upsample or increase the probability of sampling popular items. By doing so, less popular items will have more chances of being included in the sampling process. The probability of sampling negative samples could be:
\[p_i^- = \frac{f(w_i)^b}{\sum_{j=1}^N f(w_j)^b}\]where $f(w_i)$ is the number of users who have clicked on item $i$ in the training set and $b$ is a hyper-parameter to control the degree of upsampling.
However, it is not enough to rely solely on random sampling. Using random negative samples only allows the model to learn coarser-grained differences. For instance, the model can correctly recommend video games to game lovers but cannot recommend a specific game to the user. Therefore, we need to consider hard negative mining.
Hard Negative Mining
The method for selecting negative samples depends on the scenario. For example, Airbnb3 chooses hard negative samples based on its own business logic:
- Increase the number of negative samples that are located in the same positions as the positive samples.
- Increase the number of negative samples that hosts reject.
However, not all business logic can have a clear signal. In such cases, we can only use a model to mine the hard negative samples. This involves using the previous version of the recall model to filter out “not so similar” <user, item> pairs as additional negative samples to train the next version of the recall model. Facebook’s research team used the following method to mine hard negative samples offline1:
- generate top $K$ results for each query.
- select hard negatives based on hard selection strategy.
- retrain embedding model using the newly generated hard triplets.
- the procedure can be iterative.
The researchers discovered that, rather than using hardest examples, sampling between rank 101-500 led to the best model recall. While the offline stage uses the entire item set as the candidate pool, the online stage uses a set that contains the positive samples of other users in the same mini-batch. Note that hard negative samples are only a supplement to the easy negative samples.
Are non-click impressions entirely useless?
Todo